How the SmartItem™ Improves Tests

Written by David Foster, Ph.D.
Reliability
In the beginning, one of my biggest concerns about SmartItem technology was how it would contribute (or not) to the reliability of an exam. As you may have learned by now in previous blog posts, booklets, or e-books, each SmartItem can be presented in tens of thousands–even hundreds of thousands–of ways. No test taker sees the same thing, as this effect is compounded by the number of SmartItems on each test. Logically and psychometrically, I thought it would all work out, but I was looking forward to seeing the first calculations of reliability from an information technology certification test, one of the first to facilitate the use of the SmartItem.
The test had 62 SmartItems, and the reliability statistic was based on the responses to those items by 70 individuals. The reliability was calculated at .83, a decent and acceptable result. Whew!
Item Fitness
For this IT certification exam, a field test was conducted and item analyses were run to evaluate the performance of the SmartItems. For each SmartItem, we calculated the p-value (proportion of examinees answering the item correctly) to see which questions were too easy or too difficult. We also used the point-biserial correlation as a measure of the SmartItem’s ability to discriminate between more competent and less competent candidates. These are statistics based on classical test theory (CTT) and are routinely used to evaluate items in most of the high-stakes tests that are used today.
My first peek at these data was gratifying. The analysis looked… well… normal. I’ve seen hundreds of these analyses over my career, and this set looked liked the others; some items performed better than others, with most performing in acceptable ranges. A small number performed poorly, which is to be expected. Of the 62 SmartItems, only 4 have p-values below .20, indicating that these 4 might be too difficult to keep on the exam. In addition, only 8 items had correlations close to zero. The large majority, therefore, performed as designed and built.
Given that these were SmartItems–and therefore were viewed differently by each candidate–it was wonderful to see that they could serve competently on a high-stakes certification exam. Based on individual SmartItem statistics, it isn’t too surprising that the resulting reliability was high.
Comparability of the SmartItem with Traditional Items
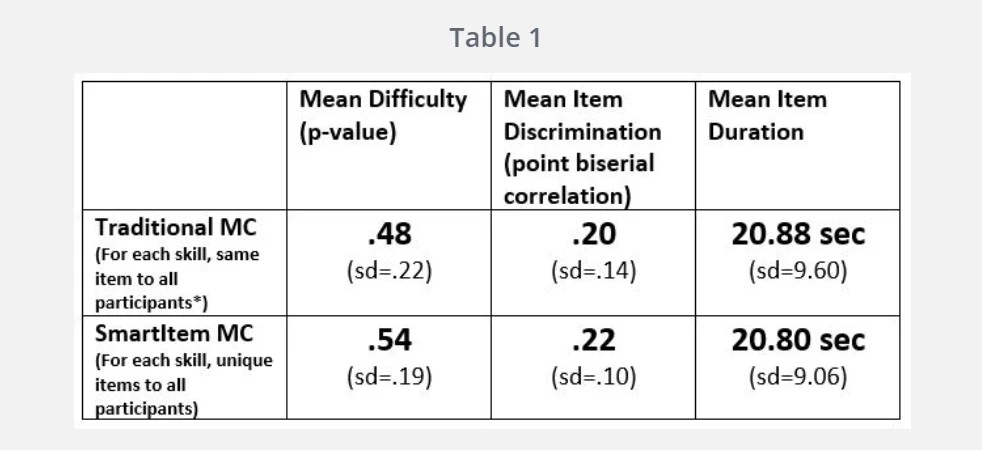
After this, our interest peaked; we wanted to know how well multiple-choice SmartItems compared with traditional multiple-choice items while covering the same 21 skills. Hence, we created a 21-item test based on the popular HBO series, Game of Thrones (GoT). Questions covered the content of Season 1 and included items designed to measure a variety of cognitive skills. The traditional multiple-choice item for each of the 21 skills was created as the first SmartItem rendering, and it covered the same skill. From almost 1,200 GoT fans who volunteered to take this test, here are some classical statistics averages:
CONCLUSION
Based on the above data, here are some conclusions I would draw:
- The average p-value for SmartItems ultimately represents an average of its renderings randomly created for the 1,200 participants. This is not expected to be the same as the traditional multiple-choice (MC) item, as the traditional MC (being fixed and being the first rendering) could have easily resulted in 21 items that were slightly more difficult in actual content. This does not mean that the SmartItems are generally easier, or that they’re more difficult than traditional MC counterparts.
- There is no difference in measures of discrimination.
- There is no difference in measures of average item duration.
- The advantages of SmartItem technology over traditional items are many. In addition to the above findings, SmartItem technology almost completely removes security problems that are found with traditional multiple-choice items, and test development and maintenance costs are drastically reduced by utilizing the SmartItem. The SmartItem can even motivate appropriate test preparation by both learners and teachers alike.
You can learn more information and read additional case studies in our e-book, SmartItem: Stop Test Fraud, Improve Fairness, & Upgrade the Way You Test. If you’d like to view live examples of SmartItem technology, please view the SmartItem booklet or reach out—we will gladly show you more about the SmartItem and demonstrate how it can benefit your tests.
David Foster, Ph.D.
A psychologist and psychometrician, David has spent 37 years in the measurement industry. During the past decade, amid rising concerns about fairness in testing, David has focused on changing the design of items and tests to eliminate the debilitating consequences of cheating and testwiseness.
He graduated from Brigham Young University in 1977 with a Ph.D. in Experimental Psychology, and completed a Biopsychology post-doctoral fellowship at Florida State University. In 2003, David co-founded the industry’s first test security company, Caveon. Under David’s guidance, Caveon has created new security tools, analyses, and services to protect its clients’ exams.
He has served on numerous boards and committees, including ATP, ANSI, and ITC. David also founded the Performance Testing Council in order to raise awareness of the principles required for quality skill measurement. He has authored numerous articles for industry publications and journals, and has presented extensively at industry conferences.
CURIOUS IF SCORPION IS THE RIGHT PLATFORM FOR YOU?
Tell us a little about your organization’s needs and request your free demo today!